Where will machine learning go after transformers on GPU? The history and future of Machine Learning hardware
I go through the history of microprocessors, and how they enabled machine learning tasks over the decades. I extrapolate to the next decade of computing, focused on machine learning/AI.
TL;DR: Moore’s law is rapidly dying off.
RAM speeds are becoming the bottleneck to performance. Performant hardware in the future will rely more on several different processors (CPU, GPU, tensor cores, etc.) and moving around cache levels and DRAM location on those processors.
I’m excited about Tensttorrent hardware to replace NVIDIA tensor cores.
I’m also excited about uses of modern SSDs (NVMe and PCM) as basically RAM to enable large datasets (>10TB) on a single consumer grade machine at >50GB/s.
I’m not hopeful about meaningful progress in the core foundation models for LLMs. I’m also not hopeful about another architecture being a paradigm changer like transformers.
It’s impossible for something to grow exponentially forever[1]. To forecast a paradigm shift, you need to know where you are on the sigmoid-shaped curve of a technology’s growth curve:

In machine learning, transformer-based models have brought a paradigm shift: practically all the AI breakthroughs in the last 4 years were due to Transformers..
The hype on transformer models and LLMs is so intense that Nvidia is now the most valuable company in the world. By the end of this article, you should consider this absurd. Long term trends in computing hardware are strongly against Nvidia having a monopoly in machine learning for very long.
Note: If you enjoy my blog, you can follow its mirror on substack for new posts:
The Bitter Lesson
Rich Sutton’s Bitter Lesson is an 8 paragraph blog post. It’s also more important than almost anything else written on AI in the last two decades.
This is the bitter lesson:
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.
Why is the bitter lesson correct?
Coming up with new ideas is hard. Trying a billion ideas per second is easier.
For the last 70 years, the rate of progress in computing power, following Moore’s Law, has been faster than the rate at which our smartest computer scientists could come up with better ideas.
Smart ideas turn out to be a waste of time if you can just guess a billion times a second until you get it right.
For machine learning to work, you need:
-
A way to make guesses really, really fast on the problem you’re solving
-
Something that tells you if your guess is right[2].
- Something that points you in the right direction to update your guesses[3].
- A usecase, otherwise people will stop giving you money to keep guessing
This Article
The bitter lesson isn’t a fundamental law of the universe. It’s been true because computing power has been growing exponentially for 60 years. Will the bitter lesson stay true into the future?
First we’ll go through the history of computing power and how its evolution has led us to giant transformer based models in 2024.
Second, we’ll look at the software side of machine learning, why it’s driven by hardware progress (not the inverse), and what different model architectures are promising in the future.
Lastly, we’ll talk about what I think is promising in the hardware space.
A History of Computing Power
Computers can only do two things:
-
Move electrons from one electrically charged object to another
-
Flip 0’s to 1’s on those objects [4]
Hardware basics:
CPUs have registers in them on which they operate. Those registers get their data from RAM, and the RAM gets its data from hard drives[5].
In the early days of computing, CPUs were slower than the RAM that fed them data. This might seem like trivia. It’s the kind of trivia that’s worth trillions of dollars now.
In an Intel 80286 (1982), the memory cycle is slower than standard RAM. RAM was so much faster than CPUs that the 6502 actually used some of its RAM as additional CPU registers.
(1989) The Rise of the Data Bottleneck
As transistors got faster and smaller, the speed of flipping bits in registers increased at a faster rate than moving electrons around memory.
Moore’s Law roughly had computing power doubling every two years. RAM speeds double roughly every 7 years.
The divergence is visible if we translate the compute in GFlops to GB/seconds and compare it to the RAM bandwidth in GB/s for consumer grade hardware:

By roughly 1995, it’s common for the processor to be stuck waiting for data from RAM.
Hardware adapts to RAM being relatively slower
RAM being slower than the CPU motivates innovations to avoid “stalling” the CPU from work:
- Data caches hold data closer to the CPU, so roundtrips to RAM are reduced. The first CPU with an on-chip cache is the Intel 486 (1989). Here’s how caches look in an Intel i7-970 (2011):

- CPUs started prefetching. CPU performance in 2005-2024 is largely about various clever ways send the data from RAM to the caches before it’s even needed. Features like Out-of-order execution, speculative execution and branch prediction becoming increasingly important[6].
The memory hierarchy dominates everything now
In 2024 we’re still in the era of the Data Bottleneck, with no end in sight. The Memory Hierarchy reigns king over computing performance.
The memory hierarchy is the pyramid of cheaper, larger and slower forms of data storage available to a processor. Here are the hierarchy’s latency numbers for a modern CPU and GPU:

(1997) The rise of modern machine learning
1997 might seem like an early date to mark the start of machine learning’s dominance, but it’s where two critical problems found solutions: datasets and price of computing power.
The internet & Datasets
Before the internet, getting a good dataset to do machine learning meant a labor intensive project to gather, annotate and clean data. In 1998, MNIST was one of the best datasets for image recognition:

As the internet grows, big datasets become common. Projects like Imagenet start using crowdsourcing for the labor intensive parts of dataset generation.
Price of compute
Before the 1990s, getting enough GFLOPs of compute power to make machine learning projects successful was incredibly expensive .
AI efforts in the “AI winter” of the 1980s were mostly systems that tried (and failed) to manually encode human intuition. W
With cheaper GFLOPs in the late 1990s, compute-heavy projects like DeepBlue become feasible.
Machine Learning as data filtering
With the internet, the main commercial usecase for machine learning came up: filter out what’s relevant from the mountain of internet content. The 2006 Netflix prize competition for the best movie recommendation algorithm is an example.
However, the first massive success for [internet + machine learning] is obvious. It’s PageRank, the initial algorithm behind Google search[^prank]
Note something: Google built its search engine using commodity hardware in DIY’ed racks in a garage. Breakthroughs are most often made by industry outsiders experimenting with stuff that has somehow become cheap enough and good enough for something completely innovative.
(2005) Death of Dennard Scaling
Around 2005, a crack in computing’s exponential power growth appeared: You can’t put too much electricity in too small of an area: it creates overheating. Dennard Scaling, the constant increase in CPU’s GHz clock speeds stalled.
We can see this on the relative graph between CPU speed (frequency, in orange) and # of transistors (green):
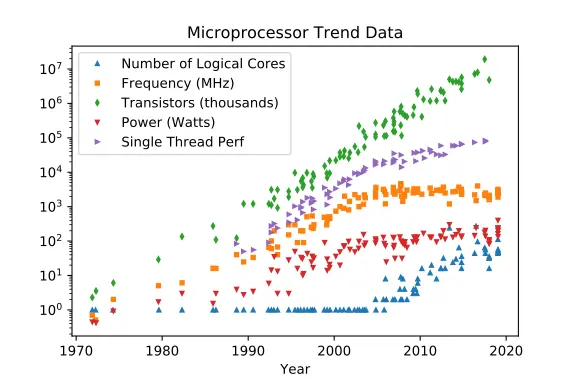
As CPU transistors became smaller than roughly 40nanometers[7], CPU clock speeds and the amount of watts we throw at them (called “thermal design power”, or TDP) stall:
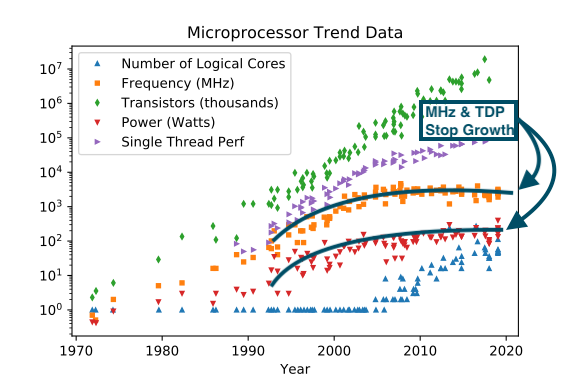
The growth has been pretty close to 0 since. The Pentium 4 ran at 3.8GHz in 2004. I’m writing this post in 2024 with an Apple M2 processor running at 3.7GHz.
The death of Dennard Scaling wasn’t the end of the computing power growth, though. CPU designers have tricks up their sleeves to mitigate this issue. But to leverage the exponential growth of computing, it’s necessary to start using new paradigms.
Let’s take a detour into methods to improve algorithm speed despite stalled CPU clock speeds:
Workaround 1: Do more stuff at the same time (concurrency)
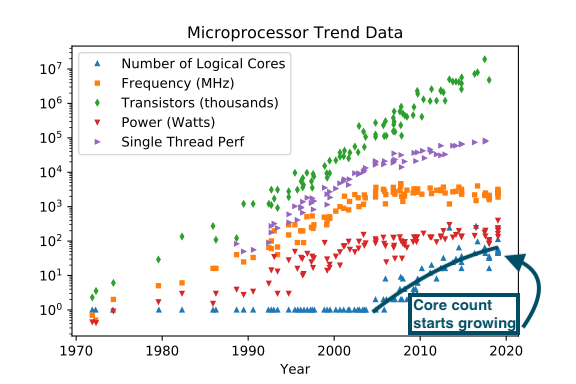
If your processor spends its time waiting for data, you can have it do multiple jobs concurrently. This way, the processor stays busy. Processors with multiple cores and hyperthreading become the norm after Dennard scaling broke:
If you have a long queue of logically separate tasks, life is good. Concurrency is great for a web server, a database, or an operating system. But to make an algorithm iterate faster, it’s not a panacea.
First, a classic problem. While one woman can make one baby in 9 months, nine women cannot make one baby in 1 month. The computer science name for this concept is “Amdahls law”. If there is any necessarily sequential part in an algorithm, it will bottleneck the entire task.
Second, writing concurrent code is really hard. Programmers already write bad sequential code. Concurrency bugs like race conditions and deadlocks are even harder to reason with. Also, while some languages like Erlang and Go are designed around concurrency, but most aren’t[8] and make concurrency harder than it already is.
Workaround 2. Do a Henry Ford (Pipelining)
Pipelining a task creates concurrency.
Casey Muratori has a good example: having both a washer and drier for clothes. Imagine you have 3 sets of clothes to wash and dry, and both the washing and drying machine takes one hour to run. Grade school math tells us this should take 3*2 = 6 hours. Anyone who’s washed clothes knows this can actually be done in 4 hours by using the washer and dryer at the same time on separate loads.
Pipelining create concurrency by slicing a task horizontally across time, instead of running separate tasks in parallel.
In practice, CPUs use pipelining heavily. Modern CPUs all execute out-of-order, in part to increase pipelining efficiency. However, it’s rare for a programmer to pipeline an algorithm into parallelism.
The issue with pipelining for programmers is that each step has to communicate its results to the next step. As we know, data movement is now the main bottleneck in computers. So pipeline step communication often becomes a bottleneck. In fact, it’s often more efficient to fuse pipeline steps together because it reduces RAM round-trips.
Workaround 3: Do a bunch of things at once (SIMD parallelism)
SIMD Parallelism means “Single Instruction, Multiple Data”. The processor transforms many objects at once, instead of one-by-one.
The SIMD approach trades off latency to increase bandwidth. SIMD works especially well on math objects like matrices and vectors. Linear algebra operations generally mean doing the same operation on a whole vector of numbers. Most machine learning code is in SIMD form.
GPUs are built around this concept - they’re fundamentally made to process linear algebra for 3d graphics, after all. Most CPUs also have SIMD capabilities as well, though.
The drawbacks to SIMD are obvious. Many algorithms can’t be parallelized easily. It’s actually possible to do much more in parallel form than you’d think, though. For instance simdjson proved it’s even possible to parse JSON in SIMD parallel form. But I would consider this a “feat of engineering” - I would not expect mere mortals to come up with the kind of dark magic Daniel Lemire is capable of.
There’s also the issue with wasted performance on anything that ressembles an if branch:
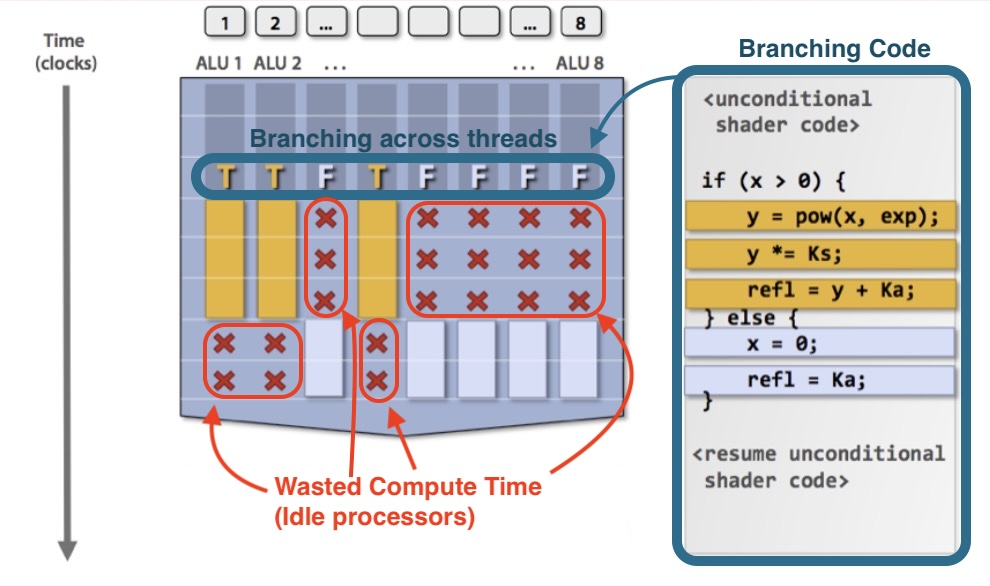
We’ll talk more about SIMD branching issues when we come back to transformer models.
(2012) The Rise of the Neural Net
Neural networks have existed since the 1980s, they became useful in 2012,
In 2012, AlexNet steamrolled the imagenet competition. Alex Krizhevsky used a ConvNet trained on two Nvidia GTX590s for a week. AlexNet had half the error rate of the 2nd best imagenet entry:

AlexNet was the first huge deep learning success. Since around 2004, there were efforts to leverage GPUs on training neural networks. GPUs are matrix processors after all.
In 2012, deep learning exploded effectively overnight, and hasn’t slowed down since. Let’s go back to our chart tracking the growth of compute, to see where AlexNet fits in:

This isn’t to take away from Alex Krizhevsky, but it was a matter of time before GPUs started dominating deep learning. The inflection point in GPU compute power made it inevitable.
(2014) Moore’s law coughs: the diagnosis is terminal
Moore’s law is dying.
Here’s an anecdote: I bought a i7-5775c in 2015 for my gaming computer. To this day, I haven’t felt a need to upgrade it. The 5775c was a fortunate buy, but not upgrading a CPU for a decade was previously unthinkable in the history of computing.
People commonly think Moore’s law is about how many transistors we can cram onto a chip. Moore’s law was really about the costs to put transistors on chips:
The complexity for minimum component costs has increased at a rate of roughly a factor of two per year.
- Gordon Moore (1965)
In the last 10 years, the minimum costs of components have stayed roughly similar, while the growth rate of performance on a single core is slowing down:
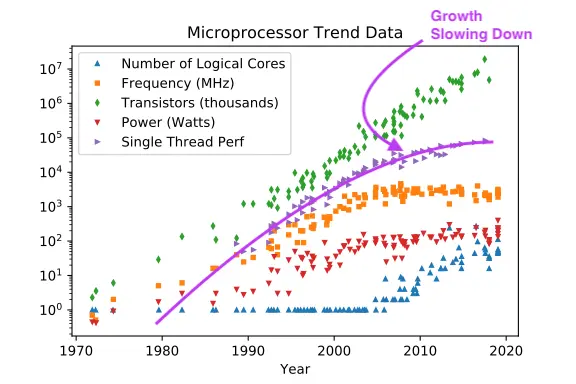
Somewhere in the 2010s, the transistor cost improvements from Moore’s law have turned the second inflection point of our sigmoid curve.

2020s and beyond: The death of GPU scaling is coming, where do we go next?
I believe someone buying a GPU in the next ~3 years will be in a similarly happy situation where they don’t need to upgrade for a very long time.
First, notice how the frontier edge of compute power growth is dominated by GPUs:
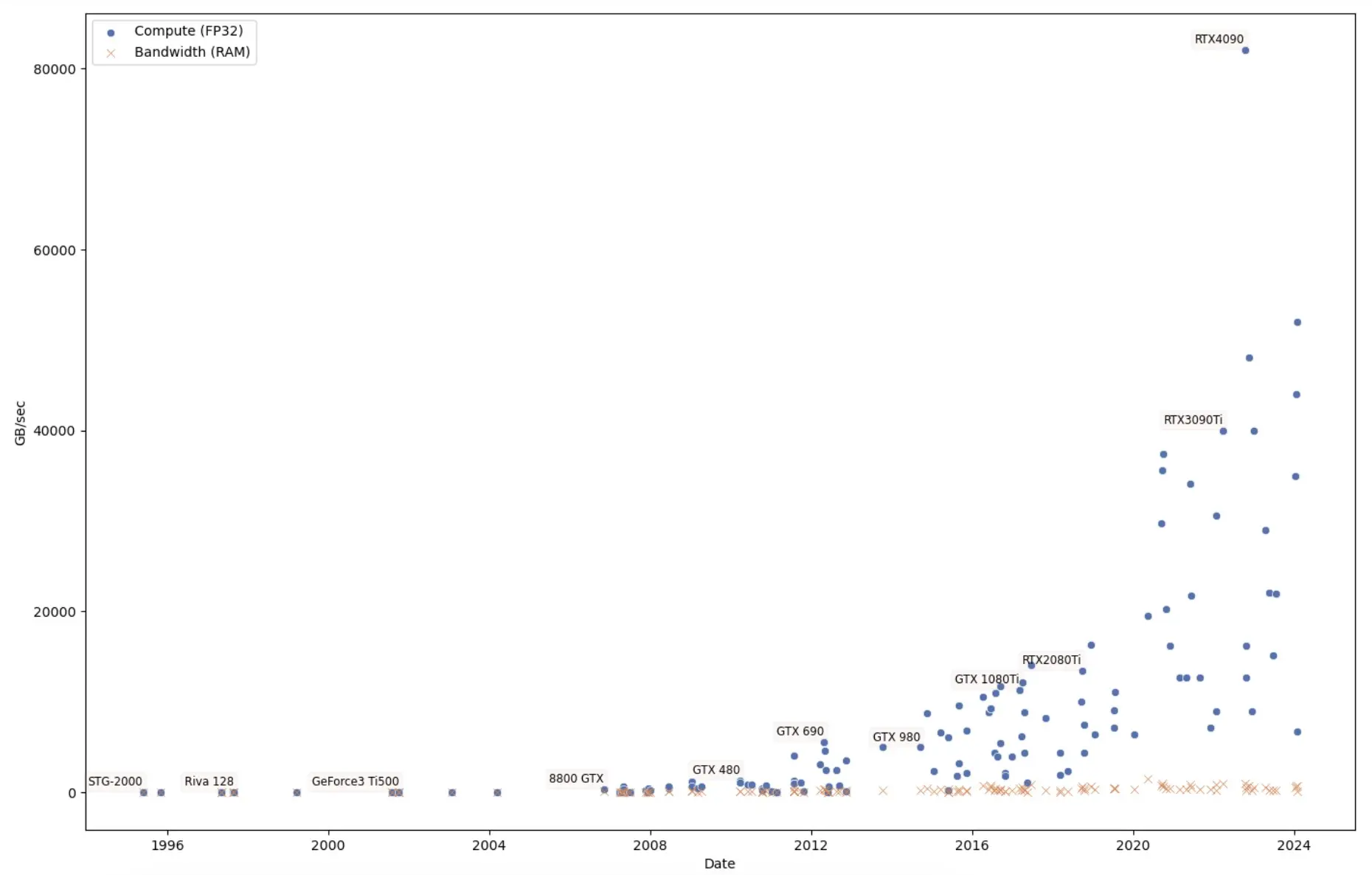
For the last 15 years, GPUs have answered the issues from the death of Dennard Scaling and Moore’s law. GPUs work on massively parallel SIMD workloads. GPUs don’t particularly care about the speed of a single thread, only the total compute throughput in GB/sec.
However, GPUs won’t be able to keep scaling. Moore’s law style growth in GPUs, where costs per compute are decreasing exponentially, will likely die somewhere in the late 2020s. Tim Dettmers explains it best:
In the past it was possible to shrink the size of transistors to improve speed of a processor. This is coming to an end now.
For example, while shrinking SRAM increased its speed (smaller distance, faster memory access), this is no longer the case. Current improvements in SRAM do not improve its performance anymore and might even be negative. While logic such as Tensor Cores get smaller, this does not necessarily make GPU faster since the main problem for matrix multiplication is to get memory to the tensor cores which is dictated by SRAM and GPU RAM speed and size. GPU RAM still increases in speed if we stack memory modules into high-bandwidth modules (HBM3+), but these are too expensive to manufacture for consumer applications. The main way to improve raw speed of GPUs is to use more power and more cooling as we have seen in the RTX 30s and 40s series. But this cannot go on for much longer.
This leads us to ask: where does computing hardware go from here?
A reminder on science
Here is an important reminder: research progress speed is a function of iteration per $.
Compare the “real” sciences to computer science. Progress in natural sciences is slow, because experimenting is expensive. A professor of physics or biology spend almost all of their time begging for money. Progress in particle physics sometimes means building a billion dollar particle collider or space telescope.
In comparison, computer science experimentation means mostly a decent laptop. At worst, sometimes, access to a cluster of GPUs.
GB/sec/$ is all you need
To make a machine learning system train fast, we can benchmark the speed in GB/sec of training data going though the system. GB/sec is the main performance metric machine learning cares about.
The bottleneck is RAM speed, of course. Worse yet: RAM prices in GB/$ have not improved for most of the past decade.:

Remember: GPU performance is bottlenecked by RAM bandwidth. This means that cost improvements of GPU compute is bounded by RAM price improvements with the current state of affairs.
This leaves us with the question: Where do we go from here?
I’ll break the future speculation section into two parts: the software side, and the hardware side. Note that I’m interested in items that could have a transformative change instead of an incremental improvement.
The Future: Software Side
Remember the recipe for machine learning:
-
Generate guesses fast
-
Data to say if the guess is correct
-
A mechanism to update guesses
The software side is concerned with the last two. Let’s start with the data.
The label problem
Even with all the data on the internet, getting good labels remains a problem. Imagenet had an army of volunteers annotate images for the relevant categories they fit.

With good labels, we can make a good model:
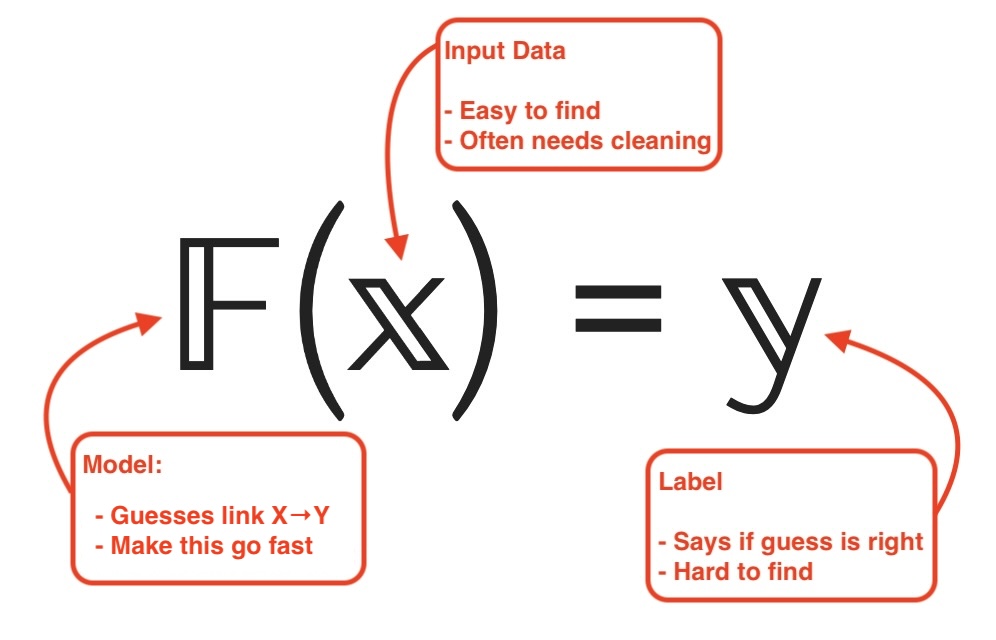
Modelling with labels is a solved problem
Between roughly 2005 and 2020, we systematically modelled everything there’s easily available labels for. There used to be a time where facial recognition wasn’t good, or you couldn’t just point your phone at a plant and have the phone tell you what kind of plant it is.
In 2024, the research frontier is rarely in making a better F when you have good y labels.
Between GBDT models and deep learning, we can extract the great predictive models from most labeled datasets without much effort.
For “normal” data science in a business, the challenges are outside the machine learning model itself: business constraints on the model’s behavior, complex interaction between multiple models, robustness to concept drift, etc.
Self-Supervised Learning
We quickly exhaust labeled datasets, and gathering a new labeled dataset is expensive. In the last 10 years, rapid innovation has moved to methods that don’t need data labels. Here are some examples:
-
Enhancement models (colorization, upscaling, denoising, etc.) work from a simple trick: make your data worse (remove colors, add noise, lower the resolution, etc.). Use the worse data as
Xand use the original high fidelity content as theylabel. -
Generative models (Language models, image generation models, etc.) outright delete a part of the data, then try to reconstruct it. Language models try to predict the next word given the previous text. Image diffusion models try to recreate an image from noise.
What to look for
I think we should look forward to new kinds self-supervision. Progress in this area is only bottlenecked by how clever researchers can be. On the other hand, any machine learning idea that is based around using labels will have to budget for first getting those labels.
Data Exhaustion
Here is a steaming hot take that could save several Gigawatt-Hours of electricity: LLM foundation models can’t improve that much from here. Modern LLMs are already trained on roughly everything humanity has ever written. There’s nowhere to go from here by training on more text.

We can make incremental improvements on LLM quality, large improvements on model efficiency and size, and large improvements on quality by task-tuning models (eg. instruction tuning, etc.).
Reinforcement Learning
In reinforcement learning (RL), your learning environment generates data and labels for you. If you’re doing machine learning on chess, your chess engine tells you if your move wins the game or not. The label generation problem becomes a compute problem for the game simulation.
Chess is a relatively small game, so we had all the ingredients [for AI to beat humans at chess as early as 1997](https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer)). More complex games take more compute power, so machine learning beat humans later in poker (2017), Go (2018), Starcraft (2019), or calvinball (TBD).
RL projects have usecase issues. You can spend years with a team of researchers to beat humans at starcraft, but that won’t make anyone much money, and won’t do anything outside of Starcraft. RL projects standare often more “basic research” into what’s possible. They’ve been partially transferable to robotics and things like RLHF in LLMs.
Transfer learning
Computer vision and NLP started becoming inevitable once transfer learning became easy. One of the most prescient blog posts was NLP’s ImageNet moment has arrived by Sebastian Ruder (2018) where he laid out that transfer learning was achievable for language modelling.
Reinforcement learning and graph neural networks have issues with transferability.
While learning poker might help humans make good decisions under uncertainty, a poker AIs won’t help make business decisions. A Starcraft AI doesn’t transfer to moving troops on a real battlefield efficiently.
If RL models find a way to transfer learning to new tasks, I would start paying serious attention.
RL and AGI
Any serious attempt at a general AI (AGI) will eventually have to plug into a real environment and do reinforcement learning from the environment’s feedback.
You can bootstrap a model by having it emulate the behavior of something you consider intelligent - this is what LLMs are doing. But LLMs are a static form of intelligence - you’re not updating LLM model weights by interacting with it.
Doing RL on real environments, you’ll run into iteration cost issues. Imagine the problems training a self driving car by reinforcement learning: [9]
-
Iteration speed is expensive and slow. One forward pass in the neural net means physically driving a car around.
-
People would die as you learn not to crash. This would be sad, and the resulting lawsuits would increase model training costs
Takeaway:
I don’t expect rapid breakthroughs in AI projects that learn from real environments. Self driving cars have improved at a slow pace, and so has robotics AI. This is not to say these projects are wasted effort. Slow growth is still growth! But calibrate expectations to the fundamental forces underlying progress.
Information / GB / s
Here is an interesting finding: it seems that spoken human languages transmit information at similar rates (~39 bits/s). Languages that have simpler structures tend to be spoken faster, and vice versa, to converge to an information rate that’s comfortable for conversation.
When I said GB/s/$ is all you need, that was incorrect. information per second per dollar is the metric we care about. There are still gains to be made in increasing information density. Between our data, models and software, we operate at suboptimal information rates.
Data Gains
Think about how information dense written language is. The number of bytes the word “dog” takes up [10] is minuscule versus a picture of a dog [11]:

Being so dense with information, text lets the GB/sec data bottleneck be saturated by more relevant information than by moving images or videos around RAM.
Improvements in input information density could improve modelling on images/videos/3d models.
On the information inefficiency of transformers
Attention is a filtering mechanism - it devolves to a pointer for what token to pay attention to. As model sizes grow, attention layers become very sparse:
[Above 7B model parameters] … attention layers become very sparse. The attention is very concentrated so that just a few sequence dimensions determine the top probability and the overall probability mass. Almost all sequence dimensions have zero probability. However, this is still context-dependent, and the transformer seems to be “unsure” what to attend to for some sequences.
This makes intuitive sense: the attention layers in a LLM need to route model knowledge to what’s relevant for this particular piece of text. Most knowledge in the model is not relevant for the current piece of text.
Imagine that you had to download all of wikipedia anytime you looked up a single page. This is more or less what’s happening when a foundation model is queried.
We should feel ashamed at how wasteful transformer LLM models are. Think again about how logical branching works in a GPU:
Transformer models don’t do if/else branching, instead they approximate this behavior by having dot products on irrelevant parts of the model decay to 0. Those zero/near zero values are pseudo-branches that are inefficiently using bandwidth:

The sparsity explains why quantizing an LLM from 16bit numbers to 2-8bits works so well. You’re largely passing around the number zero. The number zero is the same whether represented with 2 bits or 16. Passing smaller amounts of data wastes less information density, so you get more meaningful results for the same GB/s of data movement.
We’re arriving at the end of improvements with this trick for transformers. First, we’re already at 1bit quantization - it’s hard to go below this limit. Second, this won’t help much for transformer training: the model learns the sparsity, but it needs to start out fully connected to learn where to disconnect.
To fix the sparsity inefficiency of transformer models when training, the hardware would need to change. You’d need to be able to learn to dynamically prune computing branches as they come up - this is something only the new tenstorrent hardware (see below!) does to my knowledge.
Advances in neural network architectures
Let me be clear: neural network model architecture does not matter much.
The main reason model architecture get so much research is because of how academic incentives in computer science function. PhDs need to publish papers. It is very expensive to create new datasets. The easiest way to get a paper out is to publish a new way of modeling an existing dataset.
If we’re modeling a sequence (eg. a sequence of text for a LLM), there are fundamentally two approaches I know of:
-
Look at everything within a context window (attention layers, transformers). This is inefficient because most information in any context is irrelevant. Also, RAM requirements grow quadratically with context size.
-
Carry a “hidden state” around, and update it as you come across tokens (RNNs). Hidden states are efficient in information density and RAM requirements, but tend to bottleneck model training. Also, despite what Andrej Karpathy would tell you, they’re hard to train correctly.
-
Newer models have a mixed attention/hidden state (RWKV, Mamba, Griffin). They might be more efficient than transformers, but they don’t particularly get me excited. There might be some even better ideas that bypass training bottlenecks of hidden state based models, but I don’t know of any yet.
Hardware: What’s promising and what isn’t
1. NVME SSDs
The first promising hardware trend is something you might not expect. The trend becomes blinding once we notice it, however. While our $/GB/sec metric has been flatlining for RAM, another computer component has had an amazing decade. Witness the SSD:
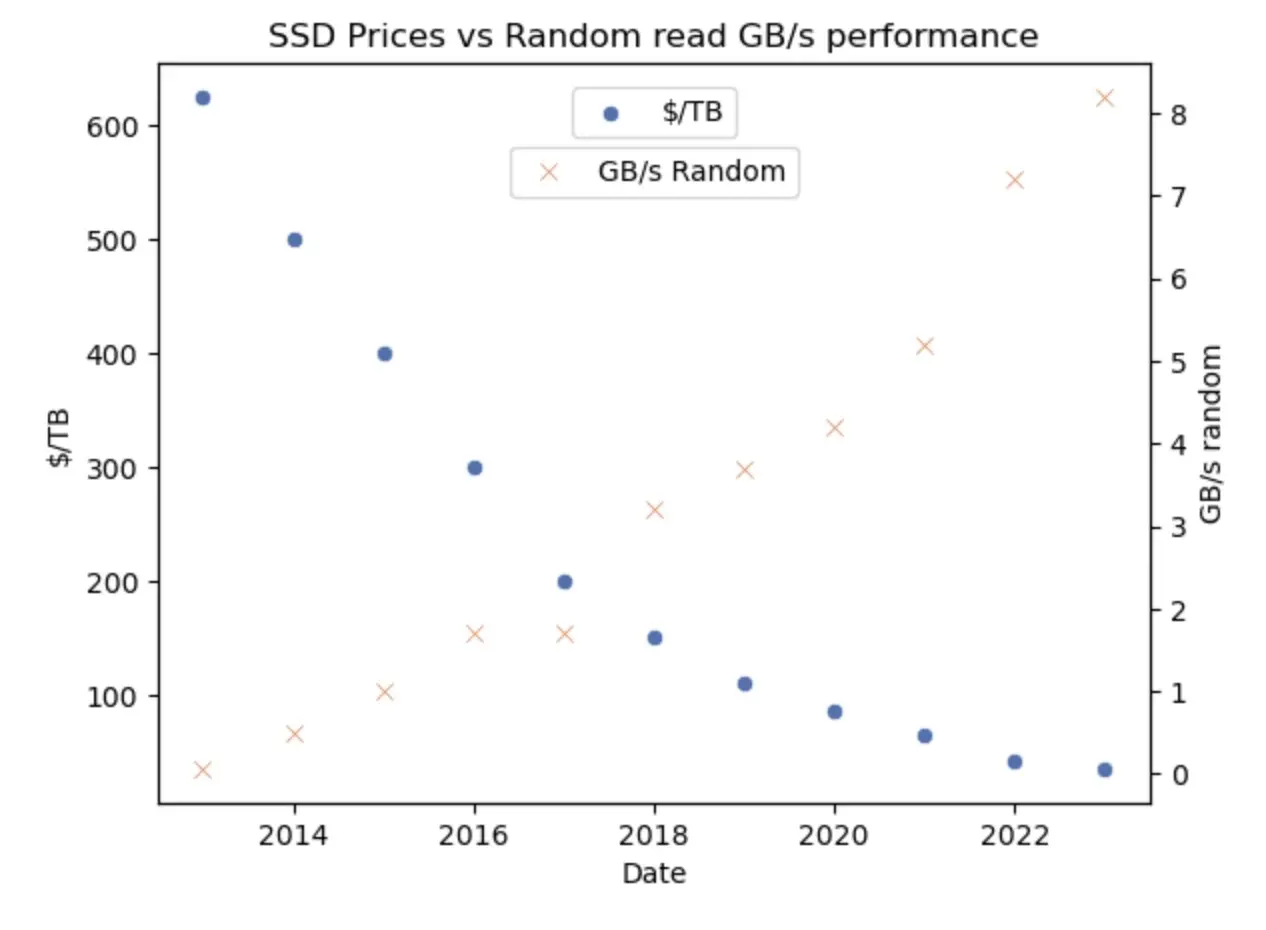
SSDs prices have dropped precipitously. In the last 2 years, something amazing happened: the price/performance ratio of NVMe drives has surpassed that of RAM.

GB per second per $ per GB is a mouthful of a metric, but it’s the fairest way of comparing RAM to SSDs in my opinion.
OK, but what can I do with a SSD?
Let me be clear:
I see a future, within ~4 years, where anyone can run almost any ML model on any dataset right from their laptop using NVMe drives
SSDs now are a nearly infinite amount of cheap RAM as far as machine learning is concerned.
I noticed this fact when writing my bitcoin price manipulation article. I used Vaex for the data analysis - a Pandas replacement that gives you the option to leave your dataset out-of-core (on the SSD). I could crunch a 100GB financial dataset in minutes from my laptop, because the dataset remained on the NVMe drive of the laptop.
You can easily put 20TB of NVMe storage in a consumer PC. You can get ~60GB/s random access bandwidth on NVMe this way 1 2. With more expensive workstation motherboards you can put 128-256TB of NVMe storage, and get throughputs in the 250GB/s range.
Caveat 1: the software
There is a reason we’re not all using NVMe drives as RAM yet: writing software that leverage them isn’t trivial.
First, to fully use SSDs, you need to code in a way that uses them well. SSDs need to have the read/write queue saturated. Having a sequential access pattern ensure the SSD queue is full, but it can also be done with parallel random access workloads.
Second, SSDs are fundamentally treated as disk drives. Operating systems have a ton of default configurations that assume disk drives are spinning pieces of metal. That legacy will slow you down - look how Tanel Põder had to fight linux configurations to get the full 60GB/s from his NVMe drives
Not you, mmap
We need to start writing more libraries that leverage NVMe drives. One mistake library developpers often make is that to jump to using mmap.
Let’s be clear: mmap is better than nothing. But it has serious performance issues especially on long running jobs:
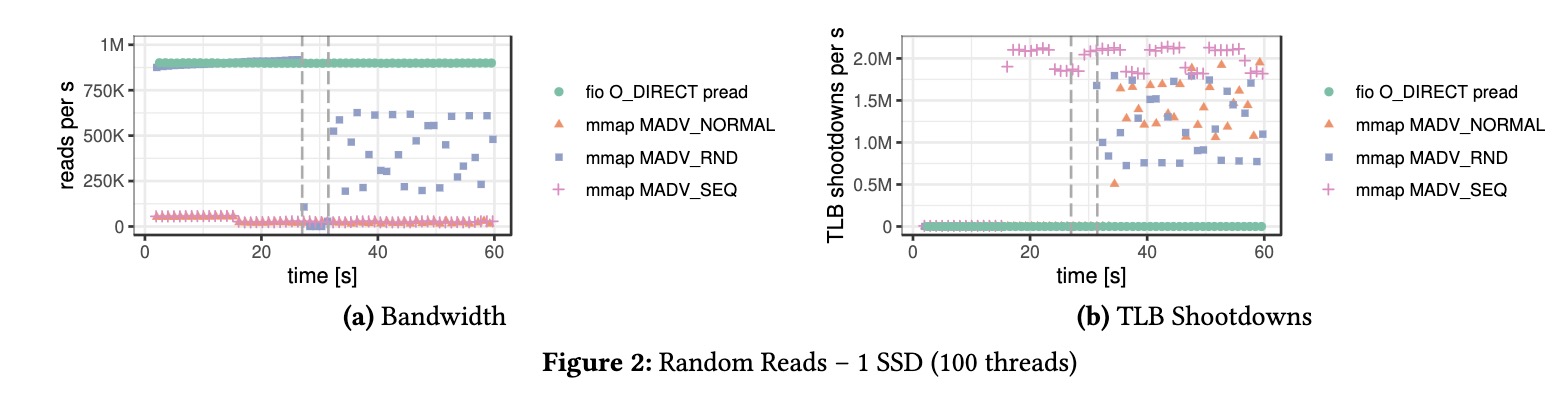
Mmap implementations maintain a memory address translation cache that becomes a bottleneck once it’s filled up. I’d encourage people who are writing new SSD based machine learning libraries to try to leverage direct IO operations to maximize the performance.
Caveat 2: the SSD quality wild west
Most consumers won’t see the difference between a low-end SSD using a SLC cache, and a high end SSD with a great controller and DRAM cache. There is a huge variance in SSD quality:
-
Sustained performance. Cheap drives are only good in short bursts, then their performance significantly degrade as their cheap drive cache gets filled up.
-
Write endurance. Cheap SSDs degrade in performance or even die altogether after a certain amount of writes. If you’re training models on an SSD this will be an issue. High-end SSDs, enterprise SSDs and Optane drives don’t have this issue.
I recommend using NewMaxx’s SSD guide if you’re buying a SSD for serious use.
PCM drives: something to watch
One exciting technology in the SSD space would be the return of Phase-Change memory (PCM). Intel Optane drives used PCM and their discontinued products from 2018 still have the best latency of any SSD.
PCM drives make economic sense if you effectively use your SSD as working memory instead of storage. I’d keep an eye on any future PCM based drives.
2. Tenstorrent and why I’m excited about it
Disclaimer: I have no affiliation to tenstorrent. I plan to buy a dev kit for various projects this summer, however.
Most AI hardware companies (groq, cerebras, etc.) don’t excite me. If you stand back and squint, most are variations on a tensor core, fiddling with HBM vs. DDR RAM, cache sizes and matrix/vector width. That’s not transformative to me, and should hit the same bottleneck GPUs will hit within a decade.
Most people only know Tenstorrent (TT) because Jim Keller is famous, and the CEO. Let’s disregard that and look at the hardware on its own merits.
Tenstorrent hardware does things differently in a way I really appreciate. Data movement has been the bottleneck in computing for 3 decades. The historical solution is to hide this problem from the programmer: add layers of cache, try to predict what’s going to going to happen to pre-fetch or execute speculatively, etc. The way AMD and Nvidia GPUs are architected shows this:
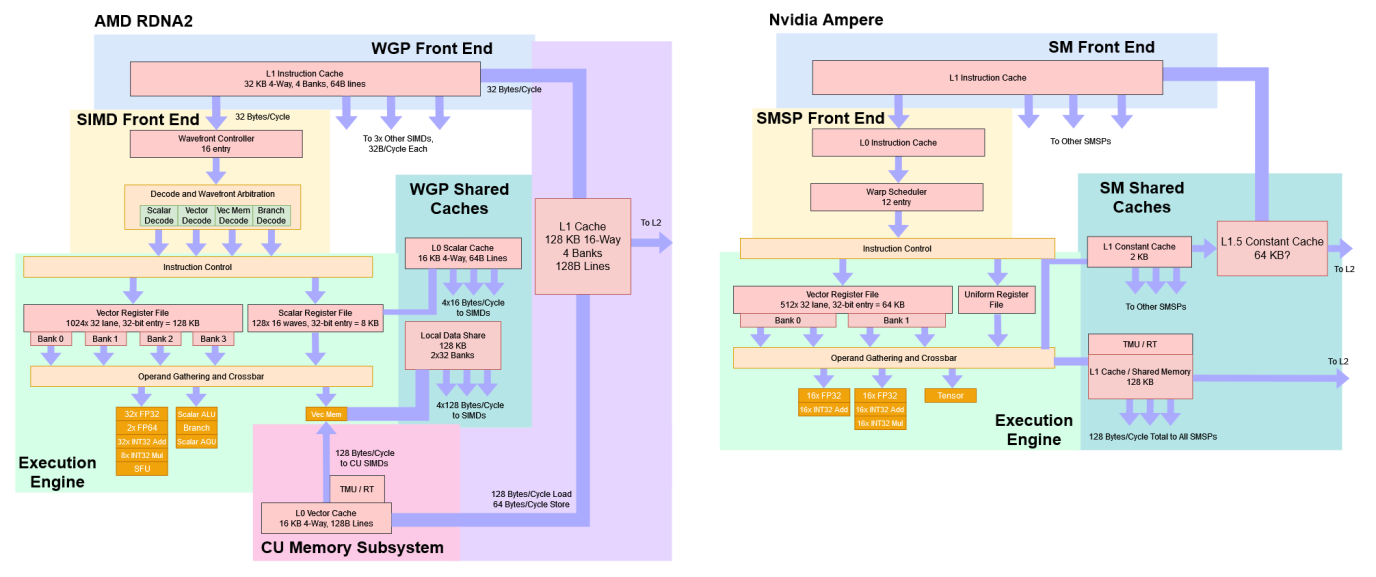
TT goes the other way. TT processors have a “flat” memory hierarchy and hand off much more of the data movement responsibility to the programmer. Take a look at the processor architecture:
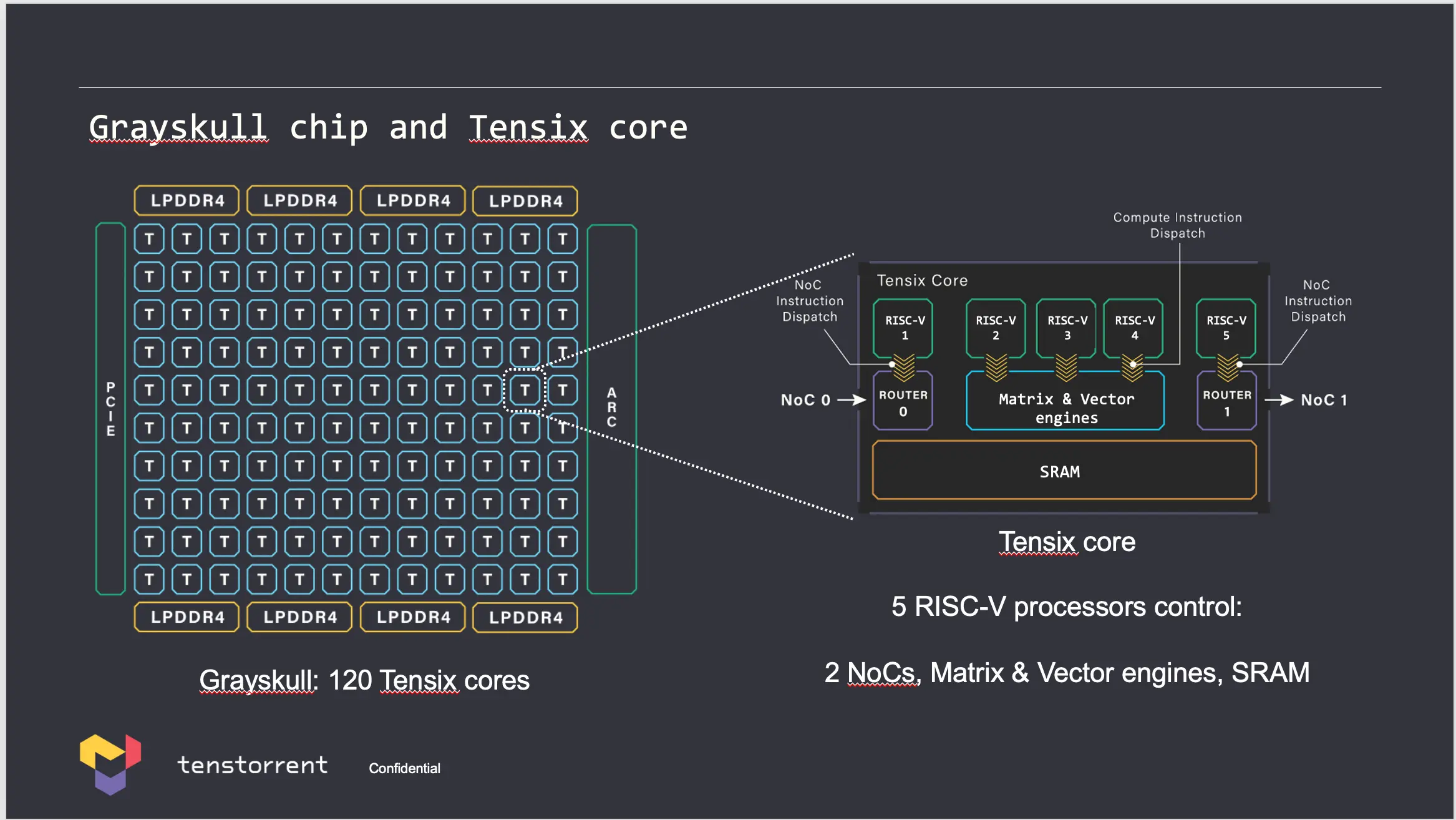
The TT processor plays on the idea of AMD Ryzen CPUs. Ryzen CPUs are built out of core complexes linked together by infinity fabric
A Tenstorrent processors has ~100 “tensix cores” in an infinity fabric style mesh. Each core has 1MB of cache, a SIMD/TPU core equivalent, and routing units to send/receive data from other cores. TT describes the advantages:
The high BW and large capacity SRAM in each Tensix core is a form of near memory compute. A Tensix core operating on its local SRAM achieves “silicon peak” of what current technology node allows for. Tensix cores are connected into a mesh via 2 NOCs, and each Tensix core can communicate with any other Tensix core in the mesh, and with off-chip DRAM, as well as Ethernet cores. GPU fracture SRAM across levels within the chip: large register files, small L1, and L2. SRAM is primarily used for re-use and pre-fetch on the way to off-chip DRAM, not as a primary form of Tensor storage and large parts of it not at the peak silicon speed. In contrast, in TT architecture, the entire SRAM is in one single level, and its significant capacity allows it be used as intermediates between operations, w/o relaying on HBM as the primary storage to hand-off data between operations.
This seems to be easily scalable as well: TT processors can be directly networked to each other.
TT and sparsity
Controlling data movement at the low level unlocks a field of possibility if you’re creative. Recall the inefficiency of training transformer models from earlier:
As a transformer model trains, an increasing amount of parameters become useless for any particular token you’re looking at.
With TT hardware, you could simply not pass the dead branch forward. If you control the data movement, you’re not forced to multiply hundreds of millions of zeros together if you know that zero will be passed down to the output.
Note that sparsity isn’t a transformer specific problem. Sparsity is inherent to foundation AI models. A foundation AI model like an LLM or image recognition model needs to encode a huge knowledge base. But any particular call of the model cares about a minuscule subset of the knowledge base in the model.
Having hardware that can dynamically prune out what doesn’t need to be computed as it happens is fascinating. Apart from foundation models, I can think of transformative uses in graph neural networks and 3d modelling [12].
You gotta let people fuck around with your stuff
The graveyard of failed hardware is filled with products that make it anywhere between annoying and impossible for outsiders to tinker with. Try tinkering with a Xeon Phi or a Power10 processor and you’ll get the idea.
Most transformative innovations were built by outsiders. If you want a new hardware product to succeed, you need to let people mess around with your hardware. Nvidia got this right with CUDA and they’ve been rewarded with a $2T market cap.
TT seems to get this right. You can order their dev from your couch right now. They have decent documentation and a responsive discord. They actively encourage hackers to try new stuff on their toys.
Conclusion
On the hardware side, I’m optimistic for NVMe drives, phase-change memory and tenstorrent hardware. I’m sober on the prospects for GPU and TPU growth, because they are constrained by RAM bandwidth, and RAM progress has stalled. On the software side, I’m optimistic for new methods of self-supervised learning, work leveraging sparsity in a more thoughtful manner.
You run out of stuff at some point ↩︎
Data, labels, etc. ↩︎
Gradient Descent, most of the time ↩︎
and vice versa, of course ↩︎
Or a network connection ↩︎
In recent years, these features have also been at the root of security vulnerabilities like Spectre and Meltdown. ↩︎
Current CPUs are in the 4-5nm range, for reference. ↩︎
Shame on you particularly, Python ↩︎
It’s natural to compare AI to Darwinian evolution - this is the only process we know of that has created human-like intelligence. One fact people miss here is that evolution’s cost is offloaded. Evolution works by lossy self-replication, so the cost of the next iteration is paid by whatever matter was ingested by the current generation to create the new generation.
The perceptive reader might ask: OK, what about an AI model that learns like a wormable computer virus?
The virus mutation rate is much faster than the human evolution iteration time of 27 years, but it’s also encumbered by hostile environments. Similarly, a wormable AI model trying to learn to hack into computer systems would run into defenses that drastically slow its growth. It would somehow need a lot of IP addresses to function. ↩︎3 bytes ↩︎
12.5MB for the raw RGB values on a 512x512 image with 16bit color depth. This can be compressed to ~50kb in jpg/webp format, which speaks to the lack of information density. ↩︎
You could use a voxel space and prune out empty voxels instead of neural radiance fields or signed distance functions ↩︎